
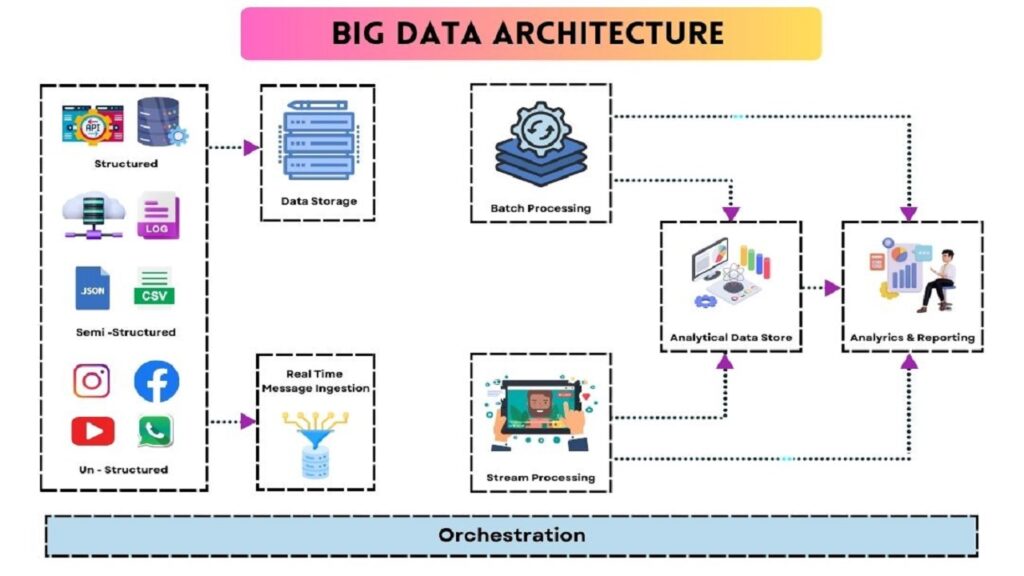
Big data architecture represents a holistic approach to addressing the challenges posed by the management of enormous datasets. It delineates a blueprint for furnishing solutions and infrastructure tailored to an organization’s specific needs. This blueprint meticulously defines the components, layers, and modes of communication integral to the ingestion, processing, storage, management, accessibility, and analysis of data.
A typical big data architecture configuration, as depicted below, encompasses various layers:
Big Data Sources Layer
Traditionally, a single database management system would grapple with the complexities of data ingestion, processing, and analysis. However, modern datasets, often exceeding gigabytes or terabytes, have outgrown the capacity of conventional architectures. Some organizations deal with datasets in the millions of gigabytes or terabytes. For instance, storage values in commodity markets have witnessed significant reductions.
Consequently, diverse data necessitates distinct storage approaches. Big data architecture addresses this challenge by providing a scalable and efficient mechanism for both storage and data processing. It accommodates batch-related data, scheduled for processing at specific intervals, alongside streaming data that demands real-time handling.
What is Big Data Architecture?
Big data systems encompass a spectrum of workload types, broadly categorized as follows:
- Batching Data: This involves processing data from static big data sources. It entails batch processing with a predefined frequency and recurring schedule.
- Real-Time Processing: Motion-based processing enables real-time handling of big data. It responds to data as it is generated, providing instantaneous insights.
- Exploration of New Technologies: Big data architecture paves the way for the adoption of cutting-edge tools and techniques, facilitating innovation and exploration.
- Machine Learning and Predictive Analysis: Harnessing machine learning and predictive analytics is an integral facet of big data architecture, empowering organizations to extract actionable intelligence from their data.
Data Sources
The foundation of any big data pipeline lies in the sources that feed into the data extraction process.
Data Storage
Data storage in big data architecture is characterized by distributed file stores capable of accommodating various format-based large files. Data lakes play a pivotal role in storing extensive collections of data in diverse formats. These data repositories house data earmarked for batch processing operations and are compatible with an array of storage solutions such as HDFS, Microsoft Azure, AWS, and GCP.
Batch Processing
In the realm of big data, batch processing segments data into distinct categories through long-running jobs. These jobs encompass data sourcing, processing, and the delivery of processed data to new files. Diverse approaches to batch processing are deployed, ranging from Hive jobs and U-SQL jobs to Sqoop or Pig, as well as custom map-reducer jobs scripted in languages like Java, Scala, or Python.
Real-Time-Based Message Ingestion
Real-time data streams require the construction of real-time streaming pipelines to meet their demands. These pipelines efficiently handle the continuous influx of data. Notable examples of message-based ingestion stores include Apache Kafka, Apache Flume, and Azure Event Hubs. These systems ensure reliable delivery and offer enhanced message queuing semantics.
Stream Processing
Distinguishing itself from real-time message ingestion, stream processing involves the handling of streaming data in the form of windows or continuous streams, subsequently writing it to a destination. Prominent tools for stream processing include Apache Spark, Flink, and Storm.
Analytics-Based Datastore
Analytical tools rely on data stores for processing and analysis. These data stores, often based on NoSQL data warehousing technologies like HBase, facilitate the retrieval and processing of pre-processed data. Hive databases provide metadata abstraction and interactive access to data, while NoSQL databases like HBase and Spark SQL also come into play.
Reporting and Analysis
The insights generated from data must undergo processing to yield meaningful results. Reporting and analysis tools, leveraging embedded technology, deliver valuable graphs, analyses, and insights crucial to businesses. Notable tools in this category include Cognos, Hyperion, and others.
Orchestration
Big data solutions often entail repetitive data-related tasks organized into workflow chains. These tasks encompass data transformation, source-to-sink data movement, and storage load operations. Tools like Sqoop, Oozie, and Data Factory, among others, streamline these operations.
Types of Big Data Architecture
Lambda Architecture
The Lambda architecture serves as a unified framework capable of handling both batch (static) data and real-time data processing. It addresses the challenge of computing arbitrary functions while minimizing latency and preserving accuracy. The Lambda architecture comprises the following layers:
- Batch Layer: This layer retains incoming data in its entirety as batch views, preparing indexes for efficient querying. It adheres to an append-only data model to ensure consistency.
- Speed Layer: Responsible for computing incremental data, the speed layer interfaces with the batch layer, reducing latency and computational overhead.
- Serving Layer: Batch views and speed layer outputs converge in the serving layer, where views are indexed and parallelized to facilitate fast, delay-free user queries.
Kappa Architecture
The Kappa architecture, akin to the Lambda architecture, accommodates both real-time streaming and batch processing data. It replaces traditional data sourcing mechanisms with message queues, streamlining data ingestion and processing. Messaging engines store a sequence of data in analytical databases, convert it into a suitable format, and make it accessible to end-users.
The Kappa architecture also simplifies access to real-time information and allows for the incorporation of previously stored data. Notably, it eliminates the batch layer found in the Lambda architecture, enhancing the reprogramming capabilities of the speed layer.
Cloud Computing Tools
Cloud computing tools leverage network-based services to deliver configurable computing resources over the internet. Leading cloud computing providers include Amazon Web Services (AWS), Microsoft Azure, Google Cloud, Oracle, IBM, and Alibaba.
Big Data Architecture Application
- Data Deletion: Big data architecture allows for the early deletion of sensitive data during the data ingestion process, enhancing data security.
- Batch and Real-Time Processing: It accommodates both batch and real-time data processing, simplifying data ingestion and job scheduling for batch data.
- Workload Distribution: The architecture disperses workload across processing units, optimizing job execution and reducing processing times.
- Parallelism: By partitioning data tables and leveraging parallel processing, query performance is significantly improved.
Benefits of Big Data Architecture
- High-Performance Parallel Computing: Leveraging parallel computing, big data architectures expedite data processing by allowing multiple processors to work in unison.
- Elastic Scalability: Big data architectures can scale horizontally, adapting to the size of workloads, and are often deployed in cloud environments, where resources are provisioned as needed.
- Freedom of Choice: Organizations can select from a variety of platforms and solutions to tailor their big data architecture to their unique requirements, existing systems, and IT expertise.
- Interoperability: Big data architecture components can be integrated into diverse platforms, enabling seamless interaction across different types of workloads.
Challenges of Big Data Architecture
- Security: Safeguarding data within the data lake is crucial, necessitating robust security measures to prevent intrusion and theft.
- Complexity: Big data architectures comprise numerous interconnected elements, each with its data pipelines and configuration settings, demanding a high level of expertise.
- Evolving Technologies: The landscape of big data technologies and standards is continually evolving, requiring organizations to stay abreast of emerging solutions and practices.
- Expertise in a Specific Domain: Big data architectures often employ specialized languages and frameworks, presenting a steep learning curve for developers and data analysts.
Also Read – From HTML to Vue.js: The Ultimate Front-End Developer Roadmap
Conclusion
Big data architectures provide a robust framework for addressing the complexities of managing vast and diverse datasets. We trust that this exploration of the prerequisites for big data architectures has been informative and enlightening.





